Infrastructure Design
Infrastructure Design is about laying the groundwork for robust and resilient applications. It involves understanding the fundamental pillars of system design and making informed tradeoffs to create systems that not only perform well but also maintain composure when faced with challenges.
Pillars of Good Design
A good design in system architecture focuses on several key principles:
- Scalability: The ability of the system to grow with its user base and increased load.
- Maintainability: Ensuring future developers can easily understand, modify, and improve the system.
- Efficiency: Making the best use of computational resources.
- Resilience: Planning for failure and building a system that can withstand unexpected issues and continue functioning.

Core Elements of System Design
At the heart of any system design are three fundamental activities related to data:
- Moving Data: Ensuring data flows seamlessly and securely between different parts of the system, optimizing for speed and security in user requests or data transfers.
- Storing Data: Beyond choosing database types (SQL/NoSQL), it involves understanding access patterns, indexing strategies, and backup solutions to ensure data is secure and readily available.
- Transforming Data: Taking raw data and turning it into meaningful information, whether aggregating log files for analysis or converting user input into a different format.
CAP Theorem (Brewer's Theorem)
The CAP theorem, named after computer scientist Eric Brewer, is a crucial concept in distributed system design. It states that a distributed system can only achieve two out of three properties at the same time:
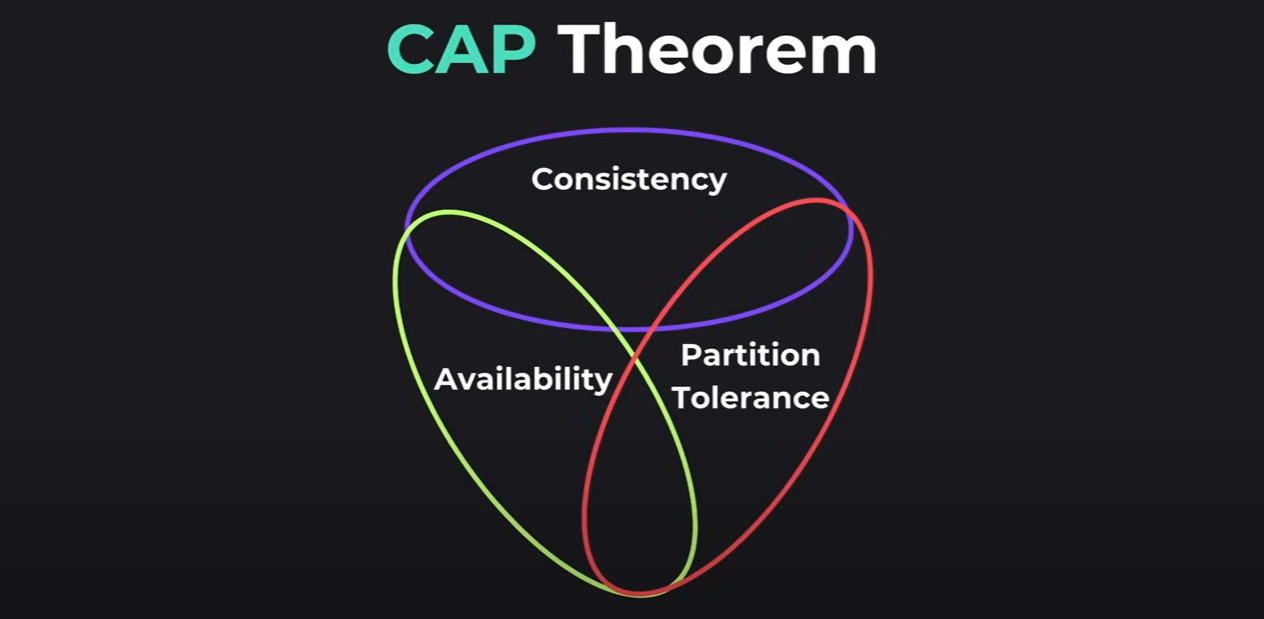
- Consistency (C): All nodes in the distributed system have the same data at the same time. If a change is made to one node, that change should be reflected across all nodes immediately (e.g., updating a Google Doc).

- Availability (A): The system is always operational and responsive to requests, regardless of what might be happening behind the scenes (e.g., a reliable online store always open for orders).
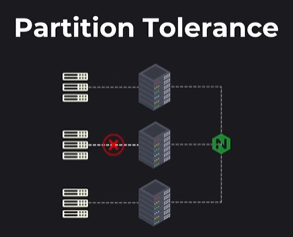
- Partition Tolerance (P): The system's ability to continue functioning even when a network partition occurs, meaning a disruption in communication between nodes (e.g., a group chat continuing even if one person loses connection).

Tradeoffs: According to CAP theorem, a distributed system must compromise on one of these three properties if a network partition occurs. For instance, a banking system prioritizes Consistency and Partition Tolerance to ensure financial accuracy, even if it temporarily compromises Availability during a network split. Every design decision comes with tradeoffs; it's about finding the best solution for the specific use case, not a perfect one.
Key Design Metrics and Management
Availability
A measure of a system's operational performance and reliability, asking: "Is our system up and running when our users need it?"
- Measurement: Often measured in percentages, aiming for "5 9s" (99.999%) availability, which translates to just about 5 minutes of downtime per year, compared to 99.9% allowing for 8.76 hours of downtime.
- SLOs (Service Level Objectives): Internal goals for system performance and availability (e.g., web service responds within 300 milliseconds 99.9% of the time).
- SLAs (Service Level Agreements): Formal contracts with users or customers defining the minimum level of service committed. Failing to meet an SLA might incur penalties (e.g., refunds for not meeting 99.99% availability).

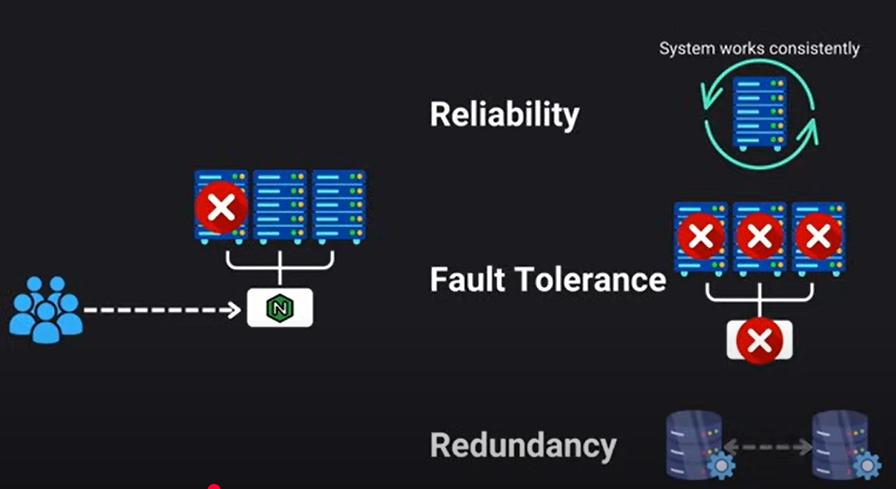
Resilience, Reliability, and Fault Tolerance
Building resilience means expecting the unexpected and designing systems to handle failures gracefully.
- Reliability: Ensuring the system works correctly and consistently over time.
- Fault Tolerance: The system's ability to handle unexpected failures or attacks without catastrophic impact.
- Redundancy: Implementing backup systems or components so that if one part fails, another is ready to take its place. This is crucial for maintaining availability and fault tolerance.
Speed (Performance)
Measuring how quickly a system processes and responds to requests.
- Throughput: Measures how much data or how many operations a system can handle over a certain period of time.
- Server Throughput: Measured in Requests Per Second (RPS), indicating how many client requests a server can handle.
- Database Throughput: Measured in Queries Per Second (QPS), quantifying the number of queries a database can process.
- Data Throughput: Measured in Bytes Per Second, reflecting the amount of data transferred or processed.
- Latency: Measures how long it takes to handle a single request; the time from a request being sent to a response being received.
- Tradeoffs: Optimizing for throughput can sometimes increase latency (e.g., batching operations increase throughput but might delay individual responses), and vice versa.

Importance of Upfront Design
Poor system design can lead to numerous issues, from performance bottlenecks and security vulnerabilities to significant refactoring challenges. Unlike code, which can be easily refactored, redesigning an entire system is a monumental task. Therefore, investing time and resources into getting the design right from the start is crucial for laying a solid foundation.
Effective infrastructure design involves a deep understanding of system requirements, conscious tradeoffs between fundamental properties like Consistency, Availability, and Partition Tolerance, and meticulous planning for performance, reliability, and scalability.
Use case: Critical for architects and engineers designing any distributed system, high-traffic applications, financial services, or systems requiring high uptime and data integrity.