Disaster Recovery Architecture Strategies on AWS
The choice of strategy should be driven by the application's specific Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
- RTO (Recovery Time Objective): The maximum acceptable delay between the interruption of service and restoration of service. This determines how quickly you need to be back online.
- RPO (Recovery Point Objective): The maximum acceptable amount of time since the last data recovery point. This determines what is considered an acceptable loss of data.
The Spectrum of Disaster Recovery Strategies
AWS outlines four primary DR strategies, each offering a different balance between cost, complexity, RTO, and RPO. They range from low-cost, higher RTO/RPO options for less critical workloads to real-time, zero-downtime solutions for mission-critical services.
- Backup and Restore: The slowest, lowest-cost approach. Data is backed up to a DR region. In a disaster, you provision a new environment from scratch and restore the data. RTO/RPO is typically measured in hours.
- Pilot Light: A step up from Backup and Restore. The core infrastructure (like databases) is kept running in the DR region, but application servers are switched off. In a disaster, you scale up the application servers and point traffic to the DR region. RTO/RPO is in the tens of minutes.
- Warm Standby: A scaled-down but fully functional version of the production environment always runs in the DR region. In a disaster, you simply scale it up to handle the full production load. RTO/RPO is measured in minutes.
- Multi-Site Active/Active: The most resilient and expensive strategy. A full production environment runs in two or more regions, and traffic is served from all of them. If one region fails, traffic is automatically routed to the healthy regions with no downtime. RTO/RPO is near-zero or real-time.
Deep Dive: Multi-Site Active/Active Architecture
For applications with the most stringent RTO and RPO requirements, the Multi-Site Active/Active strategy provides the highest level of availability and resilience. Let's explore a concrete example, as described in the transcript, that achieves this using managed AWS services.
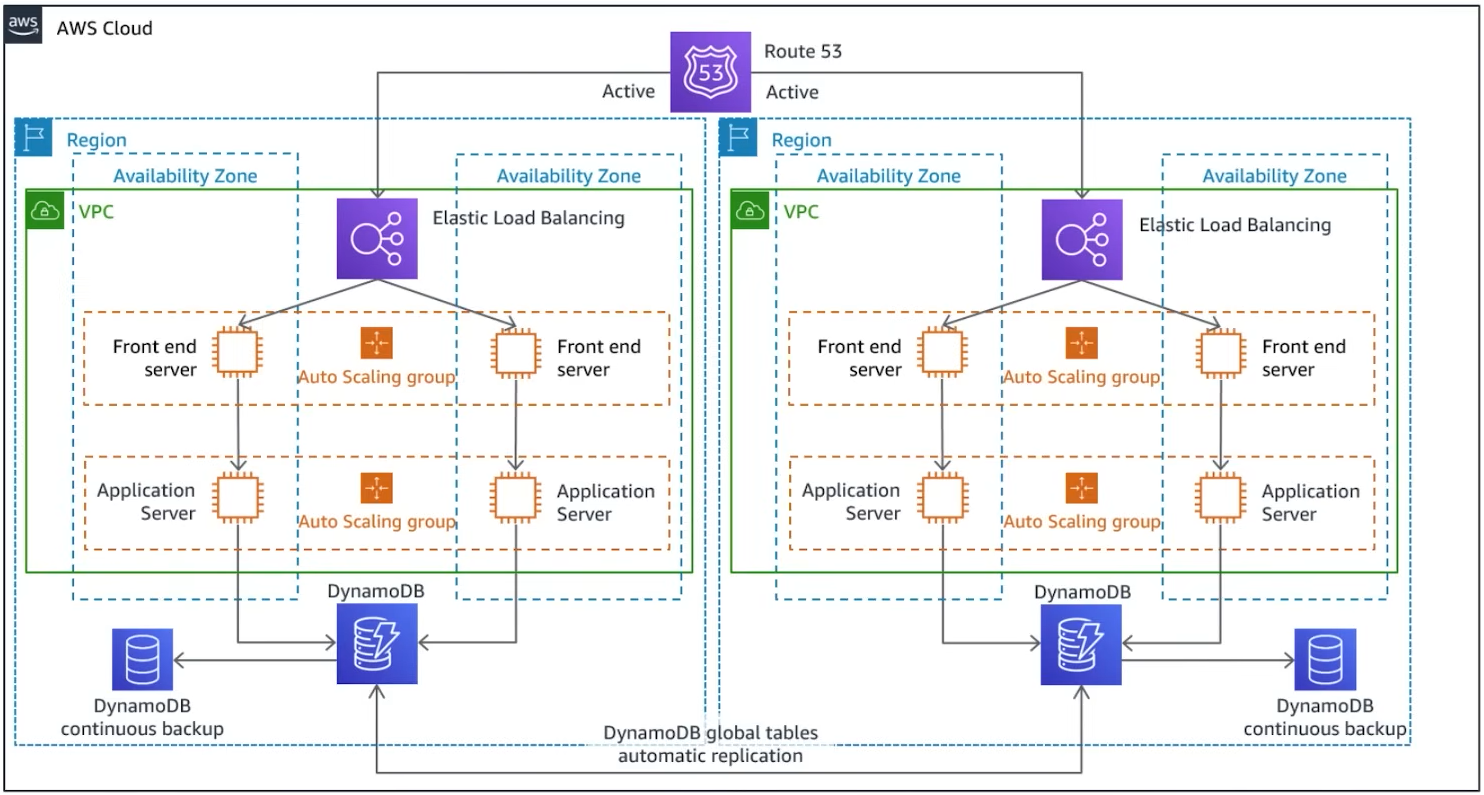
Overall Architecture Components
This architecture is designed for automatic failover and continuous data replication across two AWS Regions.
- Amazon Route 53: Acts as the intelligent DNS entry point. It is configured with a latency-based or health-check-based routing policy. This allows it to direct users to the nearest healthy region, automatically failing over and redirecting all traffic if one region becomes unavailable.
- Elastic Load Balancing (ELB): Deployed in each region, the ELB distributes incoming traffic across multiple Availability Zones within that region. This provides high availability at the regional level, ensuring that the failure of a single server or AZ does not impact the application.
- Compute Layer (Front End & Application Servers): The application servers are deployed within Auto Scaling Groups across multiple AZs. This ensures the application can scale to meet demand and automatically recover from instance-level failures.
- Database Layer (Amazon DynamoDB): The core of the data replication strategy.
- DynamoDB Global Tables: This is the key enabler for active-active data persistence. A write to a DynamoDB table in one region is automatically and asynchronously replicated to the tables in the other regions. This provides a multi-master database, meaning applications can read and write to the local endpoint in any region, with changes propagated globally.
- DynamoDB Continuous Backups (Point-in-Time Recovery): This feature provides an additional layer of data protection against accidental deletion or corruption by allowing you to restore the table to any second in the preceding 35 days.
- Alternative Database (Amazon Aurora): As mentioned in the transcript, if a relational database is required, Amazon Aurora Global Database offers similar capabilities. It provides low-latency global reads and cross-region disaster recovery with an RPO of seconds and an RTO of under a minute.
Data Flow and Failover Scenario
The power of this architecture lies in its automated response to a disaster.
- Normal Operation:
- Users' DNS queries are resolved by Route 53, which directs them to the closest or healthiest region (e.g., Region 1).
- Traffic enters the VPC in Region 1 and is distributed by the Elastic Load Balancer to an available application server.
- The application server processes the request and writes data to the DynamoDB Global Table endpoint in Region 1.
- DynamoDB automatically replicates that write to the table in Region 2, typically within a second.
- Disaster/Failover Scenario:
- A major outage makes Region 1 completely unavailable.
- Route 53 health checks fail for the endpoint in Region 1.
- Route 53 automatically stops sending traffic to Region 1 and directs 100% of user traffic to Region 2.
- Because Region 2 is already running a full, active copy of the application and has an up-to-date copy of the data (thanks to Global Tables), it can immediately begin serving all traffic.
- The failover is seamless to the end-user, achieving a near-zero RTO and an RPO of only a few seconds at most.
Comparison of DR Strategies
Choosing the right strategy requires balancing business needs against implementation costs. This table summarizes the four approaches.
| Strategy | RPO / RTO | Cost | Key Characteristics & Use Case | Common AWS Services |
|---|---|---|---|---|
| Backup and Restore | Hours | $ | Lowest cost. Suitable for lower-priority applications, development, and test workloads where extended downtime is acceptable. | Amazon S3, AWS Backup, Amazon EBS Snapshots, Amazon RDS Snapshots. Manual or scripted resource provisioning. |
| Pilot Light | Tens of minutes | $$ | Keeps a minimal "core" running (e.g., database). Faster recovery than backup/restore. Good for important but not business-critical apps. | Amazon RDS (read replica), AWS CloudFormation, Auto Scaling Groups (at min size 0), Amazon EC2. |
| Warm Standby | Minutes | $$$ | Runs a scaled-down, but fully functional, version of the application. Quicker failover. Ideal for business-critical applications. | Amazon Route 53, Auto Scaling Groups (at small size), Elastic Load Balancing, Amazon RDS (multi-AZ). |
| Multi-Site Active/Active (or Hot Standby) | Real-time / Near-zero | $$$$ | Highest availability and resilience, with zero or near-zero downtime. For mission-critical services that cannot tolerate any interruption. | Amazon Route 53 (health checks), ELB in multiple regions, DynamoDB Global Tables, Aurora Global Database. |