ML Development Environment Architecture
Objective
Give distributed teams of data-scientists and MLOps engineers a secure, repeatable, pay-as-you-go sandbox in which they can:
- Explore and prepare data interactively (Jupyter notebooks)
- Launch massive distributed training jobs (SageMaker Training)
- Store artefacts with built-in versioning (S3)
- Deploy an auto-scaling prediction API (SageMaker real-time endpoint)
- Consume the model from any client (AWS Lambda micro-service, CLI, web, mobile)
All without touching a single EC2 instance directly.
Architecture Overview
| Tier | Key AWS service(s) | Why it was chosen |
|---|---|---|
| Access & Identity | IAM, SSO, KMS | Fine-grained, transient credentials; encryption at rest with customer-managed keys |
| IDE / Notebooks | SageMaker Studio (inside SageMaker Domain) | Fully managed JupyterLab; shared EFS home directories; Git integration |
| Data Lake | Amazon S3 | Unlimited, cheap, versioned; native SageMaker integration |
| Experimentation | SageMaker Training, Processing, Experiments, Feature Store | Scale-out, spot pricing, automatic metric capture |
| Registry & CI/CD | SageMaker Model Registry, CodePipeline, CodeCommit | Approve & promote models across dev → staging → prod |
| Hosting | SageMaker real-time endpoints + auto-scaling | Millisecond latency; zero servers; A/B & shadow testing ready |
| Consumption | AWS Lambda + Amazon API Gateway | Serverless inference client; scales to zero |
| Observability | CloudWatch, CloudTrail, SageMaker Model Monitor | Logs, metrics, bias & drift detection out-of-the-box |
Component Deep-dive
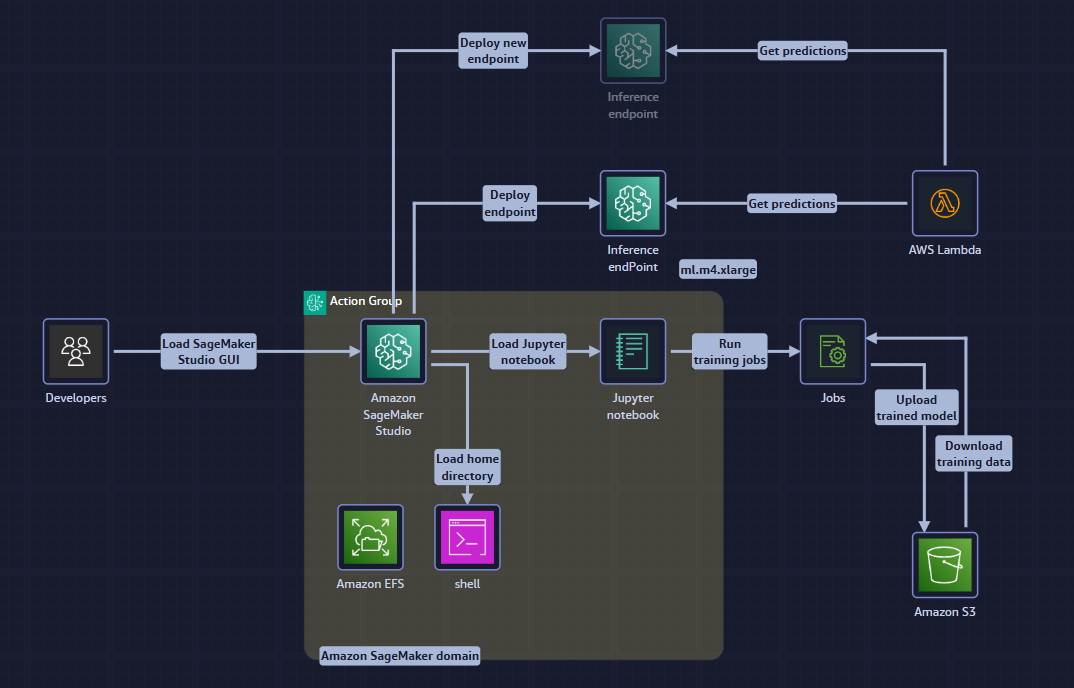
1. SageMaker Domain – the heart of the studio
- One domain per environment (dev, staging, prod)
- Lives inside a customer-managed VPC (private-only subnets by default)
- Each user gets:
- Elastic File System (EFS) home directory (5 GB free, scales automatically)
- Pre-signed URL for SageMaker Studio web UI (no SSH keys)
- Execution role scoped with least-privilege IAM policy
- Supports AWS SSO or IAM Identity Center → temporary 1-hour tokens
2. Notebook → Training → Artefacts flow
- Data scientist opens Studio notebook and pulls data from:
- Amazon S3, Amazon Athena, Amazon Redshift, on-prem (via Direct Connect), …
- After experimentation she calls
estimator.fit(inputs=s3://bucket/train/)- SageMaker spins up a dedicated cluster (1-1000s of instances)
- Spot instances save up to 90 %; checkpointing to S3 prevents job loss
- All metrics (loss, auc, etc.) stream to Amazon CloudWatch
- On completion the model.tar.gz is written to the pre-configured S3 output prefix (versioned bucket with KMS encryption)
3. Model Registry & Approval Gate
- Training job registers the new version into SageMaker Model Registry
- MLOps engineer approves via UI or CLI (
UpdateModelPackage) - An EventBridge rule triggers CodePipeline which:
- Runs security scanning (Clair on container)
- Runs integration tests (Lambda invokes endpoint)
- Promotes artefacts to prod accounts through Cross-Account S3 bucket replication
4. Real-time Inference Endpoint
- CodePipeline stage calls
sagemaker.create_endpoint_config()referencing:- Approved model artefact in S3
- Instance type / count (auto-scaling min=2, max=10)
- Data capture destination (optional: store request/response for monitoring)
- Endpoint is placed behind a VPC endpoint (no internet ingress)
- Multi-AZ automatically (SageMaker manages it)
Scaling behaviour
| Metric | Target value |
|---|---|
| InvocationsPerInstance | keep ≤ 200 |
| CpuUtilisation | keep ≤ 70 % |
| MemoryUtilisation | keep ≤ 80 % |
5. Serverless Client (AWS Lambda)
- Micro-service written in Python (boto3)
- Environment variables contain endpoint name
- Single SDK call:
runtime.invoke_endpoint(...) - Cold-start < 1 s; concurrency 1-10,000
- API Gateway front-end enforces throttling & WAF rules
- Logs and X-Ray traces ship to CloudWatch automatically
Security Controls (Defense in Depth)
| Layer | Controls |
|---|---|
| Identity | IAM roles per user; SageMaker Domain user profiles; SCPs deny .Delete on prod buckets |
| Network | VPC only; no IGW attachment to notebook subnets; SageMaker VPC endpoints for S3, ECR, CloudWatch; Security Groups allow 443 from corporate CIDR only |
| Data | KMS-CMK encrypted buckets, EFS, and EBS; mandatory bucket policies block http |
| Model | Network-isolated training with InterContainerTrafficEncryption; private endpoints |
| API | AWS WAF on API Gateway (SQL-i & XSS ruleset); throttling 1000 req/s per key; JWT authorizer optional |
| Observability | CloudTrail Lake stores 7 years; AWS Config conformance pack “SageMaker-best-practices”; Security Hub centralises findings |
Cost Optimisation Levers
| Pattern | Typical saving |
|---|---|
| Spot instances for training | 70 % |
| Enable Asynchronous Inference instead of always-on endpoint for sporadic traffic | 60 % |
| Use SageMaker Serverless Inference (preview) for < 200 ms cold-start budget | Pay only per invoke |
| S3 Intelligent-Tiering after 30 days | 40 % on storage |
| Delete dev endpoints nightly via auto-stop Lambda (EventBridge cron) | 100 % outside office hours |
Typical Data Flow Walk-through
-
Data scientist uploads
marketing.csvto s3://ml-dev-datasets -
Notebook cleans data, creates features, pushes to SageMaker Feature Store
-
Calls
estimator.fit()→ 20 ml.p3.2xlarge spot instances run for 45 min -
Model artefacts land in s3://ml-dev-models/CustomerChurn/v23/
-
CodePipeline approves model; creates endpoint customer-churn-v23
-
Lambda behind api.company.com/predict sends JSON:
{
"features": [25, 2, 0.0, 1, 0, 0, 0, 0, 0, 0]
} -
Endpoint returns
{ "prediction": 0.87, "model_version": "v23" } -
Request + response stored via Data Capture for future drift analysis.
Reference Bill of Materials (Pay-as-you-go)
| Service & Config | Unit | On-Demand Price | Free-Tier |
|---|---|---|---|
| SageMaker Studio notebook (ml.t3.medium) | hour | $0.05 | 250 h/mo first 2 months |
| SageMaker Training (ml.m5.xlarge) spot | hour | $0.134 | — |
| SageMaker real-time endpoint (ml.m5.large, 2 instances) | hour | $0.224 | — |
| S3 Standard storage | GB-mo | $0.023 | 5 GB |
| Lambda (3 GB mem, 1 s avg) | invoke | $0.0000499 | 1 M invocations |
| API Gateway HTTP | million | $1.00 | 1 M calls |
| CloudWatch Logs | GB ingest | $0.50 | 5 GB |
| Total for 10 k predictions/mo | month | ≈ $55 |
Operational Tips
- Tag every resource with
Environment,Owner,CostCenter; enforce with Config rule - Turn on SageMaker Model Monitor to auto-detect drift; alerts go to SNS → Slack
- For heavy workloads switch to multi-model endpoints or serial inference pipelines (up to 6 GB GPU memory share)
- Use lifecycle configuration scripts in Studio to pre-install Git, Conda envs, internal CA certs
- Keep entry scripts (
inference.py) under 200 ms init time to avoid scaling delays