Scaled and Load-balanced Application Architecture
This architecture demonstrates a foundational pattern for building scalable, highly available, and resilient applications on AWS. By distributing traffic across multiple Availability Zones (AZs) and automatically adjusting compute capacity based on demand, it can effectively handle both steady-state workloads and sudden traffic surges.
Scaled and Load-balanced Application Diagram
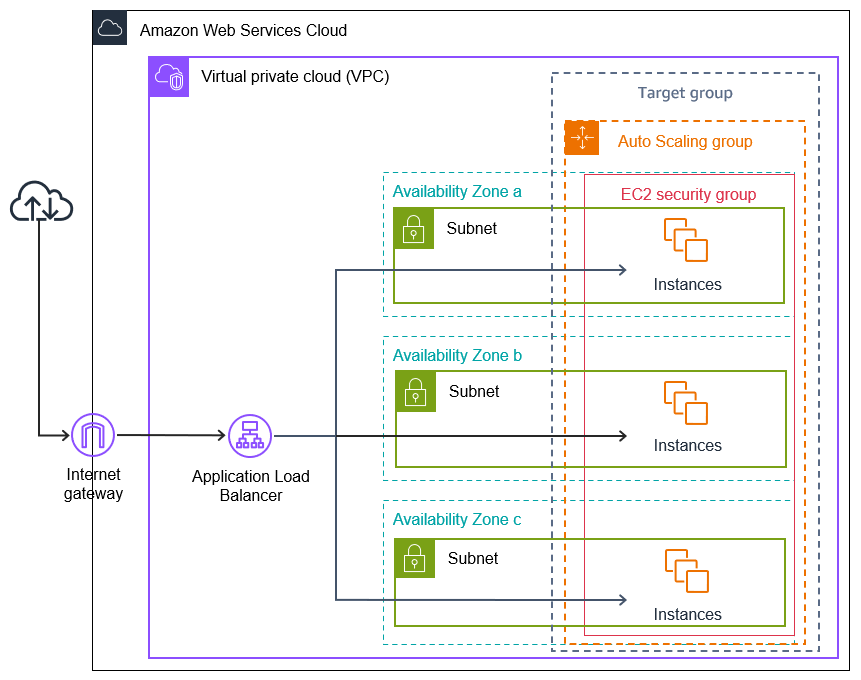
Overall Architecture Components
Let's break down the key components of this architecture and their roles in creating a scalable system.
- Virtual Private Cloud (VPC)
The isolated network environment within AWS where all resources are launched. It spans multiple Availability Zones for high availability. - Internet Gateway (IGW)
The entry and exit point for traffic between the VPC and the public internet. - Application Load Balancer (ALB)
Acts as the single point of contact for clients. It receives incoming application traffic from the Internet Gateway and intelligently distributes it across healthy EC2 instances in multiple Availability Zones. This improves availability and fault tolerance. - Availability Zones (AZs)
Distinct physical data centers within an AWS Region. Deploying resources across multiple AZs (like AZ a, b, and c in the diagram) protects the application from a single location failure. - Subnets
A range of IP addresses in your VPC. In this architecture, instances are placed in subnets across different AZs to ensure redundancy. - Auto Scaling Group (ASG)
This is the core of the architecture's elasticity. The ASG automatically adjusts the number of EC2 instances up or down based on predefined conditions (like CPU utilization) or a set schedule. It ensures the application has the optimal amount of compute capacity to meet current demand without manual intervention. - Target Group
The ALB routes requests to the targets registered in this group. The Auto Scaling Group automatically registers new instances with the Target Group and de-registers terminated ones. The ALB also uses the Target Group to perform health checks on the instances. - EC2 Instances
The virtual servers that run the application code. They are managed by the Auto Scaling Group. - EC2 Security Group
A stateful, instance-level firewall that controls inbound and outbound traffic to the EC2 instances. It acts as the final layer of network security for the application servers.
Data Flow Explanation
- Request Initiation
A user's request originates from the internet. - VPC Entry
The request enters the AWS Cloud and is directed to the Internet Gateway attached to the VPC. - Load Distribution
The IGW forwards the traffic to the Application Load Balancer (ALB). The ALB terminates the initial connection, inspects the request, and selects a healthy target. - Target Selection
The ALB distributes the request to one of the available EC2 instances in a Target Group. This distribution is spread across all three Availability Zones (a, b, and c) to ensure high availability. - Instance Processing
The request is received by an EC2 instance within its subnet. The EC2 Security Group must have a rule allowing traffic from the ALB. The instance processes the request and sends a response. - Response Path
The response travels back through the ALB to the user via the Internet Gateway. - Dynamic Scaling
The Auto Scaling Group continuously monitors the aggregate load on the instances. If a scaling policy threshold is breached (e.g., average CPU utilization exceeds 70%), it will automatically launch new EC2 instances. These new instances are automatically registered with the Target Group and begin receiving traffic from the ALB once they pass health checks. Conversely, if the load decreases, the ASG will terminate unneeded instances to save costs.
Advanced Scaling Strategies for High Traffic Events
The base architecture is robust, but for massive, predictable traffic spikes like Black Friday, Diwali, or a product launch, a more sophisticated approach is required to ensure a smooth user experience. A simple reactive Auto Scaling policy might not be sufficient to handle a sudden, vertical rise in traffic.
The Challenge: Handling Extreme Traffic Bursts
During a high-traffic event, the rate of incoming requests can overwhelm an application's resources before the Auto Scaling Group has time to react and launch new instances. The load balancer itself can also take time to scale its internal capacity. This can lead to increased latency, errors, and a poor customer experience.
Proactive and Optimized Scaling Solutions
A solutions architect would recommend the following advanced strategies to prepare for such events:
1. Load Balancer Pre-warming
An Application Load Balancer scales automatically, but this process isn't instantaneous. For extreme traffic bursts, the ALB's scaling might lag behind the traffic increase.
To prevent this, you can "pre-warm" the load balancer by submitting a support request to AWS, ensuring it has adequate capacity allocated before the event. Alternatively, you can run a gradually increasing load test ahead of time to trigger its scaling mechanism naturally.
2. Scheduled Auto Scaling
Instead of waiting for traffic to build, you can use Scheduled Scaling for your Auto Scaling Group. This allows you to define a specific time to increase the minimum and desired number of instances.
For example, you can schedule the ASG to scale out to 20 instances at 8 AM, just before a major sale begins, ensuring your application is fully prepared.
3. Optimized Amazon Machine Images (AMIs)
When Auto Scaling does need to launch new instances, the time it takes for them to become operational is critical. This is known as the "spin-up time."
By creating a lightweight AMI that includes the application and all its dependencies but excludes unnecessary libraries or services, you can significantly reduce the boot time. A faster launch time means your application can respond to demand more quickly.
4. Database Connection Management with RDS Proxy
Rapidly scaling out application instances can create a "connection storm" on your database, as each new instance attempts to establish multiple new connections.
This can exhaust the database's memory and CPU. Amazon RDS Proxy is a managed database proxy that sits between your application and your RDS database. It pools and shares database connections, improving application resilience and scalability by gracefully handling sudden surges in connections and preventing database overload.
5. AWS Infrastructure Event Management (IEM)
For critical, large-scale events, AWS offers IEM, a paid support service. With IEM, AWS experts work with your team to review your architecture, recommend operational improvements, and help pre-provision resources (like load balancers and EC2 capacity). During the event, AWS provides a dedicated team to monitor your environment and assist with any issues, acting as a strategic partner to ensure success.
6. Architectural Evolution to Microservices
For complex applications, consider breaking the monolith into microservices. This allows different components of your application to scale independently. For example, the "shopping cart" service might need to scale out far more than the "user profile" service during a sale. This granular scaling is more efficient and cost-effective than scaling an entire monolithic application.
Considerations for Kubernetes and Serverless
While migrating to platforms like Kubernetes or Serverless can offer powerful scaling capabilities, they are not "magic bullets" and come with their own complexities.
- Kubernetes
You must understand its scaling mechanisms, such as the Horizontal Pod Autoscaler (HPA) for scaling pods, the Cluster Autoscaler for adding/removing nodes, and the importance of keeping container image sizes small for faster deployments. - Serverless (e.g., AWS Lambda)
To handle sudden bursts without cold starts, you need to use Provisioned Concurrency. You must also be aware of and potentially increase service quotas for components like API Gateway to avoid throttling.
Architecture pay-as-you-go AWS services
This architecture primarily uses pay-as-you-go services. Costs will depend on traffic volume, compute requirements, and data transfer. The table below outlines the main services and their pricing models.
| Service | Tags | Role | Unit of Measure | Free Tier Rate Limit | Price per Unit After Free Tier (Approx. USD, per region) |
|---|---|---|---|---|---|
| Virtual Private Cloud (VPC) | - networking - vpc - free | Provides a logically isolated section of the AWS Cloud. | Logical Config | Unlimited. | Free. |
| Internet Gateway (IGW) | - networking - comms - gateway | Enables communication between instances in your VPC and the internet. | Data transfer out (GB). | 100 GB of Data Transfer Out (aggregated across all AWS services). | Standard EC2 data transfer out rates (e.g., $0.09/GB for first 10TB/month). Data transfer in is free. |
| Application Load Balancer (ALB) | - networking - balancer - alb | Distributes incoming application traffic across multiple targets in multiple Availability Zones. | Load Balancer hours, Load Balancer Capacity Units (LCUs) per hour. | 750 hours/month, 15 LCU-hours/month for 12 months. | Load Balancer hours: ~$0.0225/hour; LCU-hours: ~$0.008/LCU-hour. |
| Auto Scaling Group (ASG) | - scaling - compute - free | Automatically adjusts the number of EC2 instances to maintain performance and optimize costs. | Logical Config | Unlimited. | Free. You only pay for the AWS resources (e.g., EC2 instances) it manages. |
| Amazon EC2 Instances | - compute - vm | Virtual servers that run the application. The primary source of compute cost. | Instance-hours (per-second billing), Instance type. | 750 hours/month of a t2.micro or t3.micro instance for 12 months. | Varies greatly by instance type, OS, and region (e.g., t3.medium in us-east-1 is ~$0.0416/hour). |
| EC2 Security Group (SG) | - networking - security - firewall - free | Instance-level stateful firewall for controlling inbound/outbound traffic. | Rules | Unlimited. | Free. |
| Data Transfer | - networking - egress | Data transferred out of AWS to the internet. Data transfer between AZs also incurs a cost. | GB transferred. | 100 GB/month out to the internet. | Egress to Internet: ~$0.09/GB. Between AZs: ~$0.01/GB in each direction. Ingress from internet is free. |
| Amazon RDS Proxy (Optional) | - database - proxy - connection-pooling | A fully managed, highly available database proxy for Amazon RDS that makes applications more scalable and resilient. | vCPU-hours of the proxy instance. | No specific free tier. | ~$0.015 per vCPU-hour. (Price varies by database engine and region). |
Important Considerations:
- EBS Volumes: EC2 instances require Amazon Elastic Block Store (EBS) volumes for storage, which are priced separately based on size (GB-month) and type (gp3, io2, etc.).
- Monitoring: Services like Amazon CloudWatch for metrics, logs, and alarms will incur costs based on data ingestion, storage, and the number of alarms/dashboards, although a perpetual free tier exists.
- Regional Pricing: All prices provided are examples for a US region and can vary significantly by AWS Region. Always check the official AWS Pricing Calculator for the most accurate estimates.